Overview
This post discusses the evolution of MATLAB loop performance and the decreasing necessity for manual vectorization due to JIT compiler improvements. It also touches upon the use of MEX-based BLAS/LAPACK implementations for ND-array operations.
🏷️ MATLAB Loop Performance
Looping within MATLAB M-files was notoriously slow years ago due to a lack of optimization. However, modern versions of MATLAB have significantly improved loop speeds, reducing the need for manual vectorization in many cases.
It is important to note that writing loops directly in the Command Window does not benefit from JIT compiler optimizations. For optimal performance, loops should be written within scripts or functions.
🏷️ MEX-based Optimizations
In the past, self-tuned MEX codes utilizing BLAS/LAPACK were commonly used to overcome loop performance issues. Tests with mmx and mtimesx in MATLAB 2014b indicate that for-loops are no longer significantly slower in many standard scenarios.
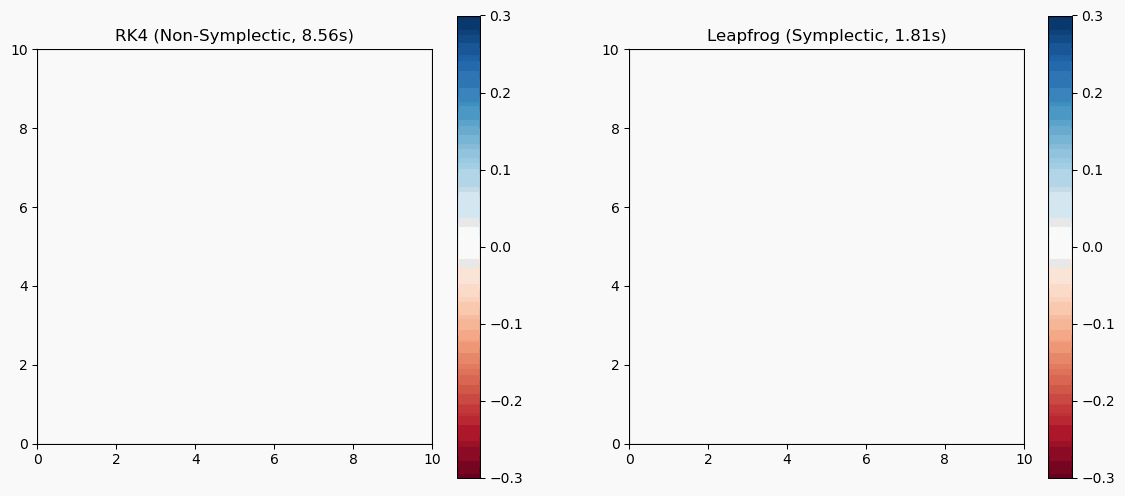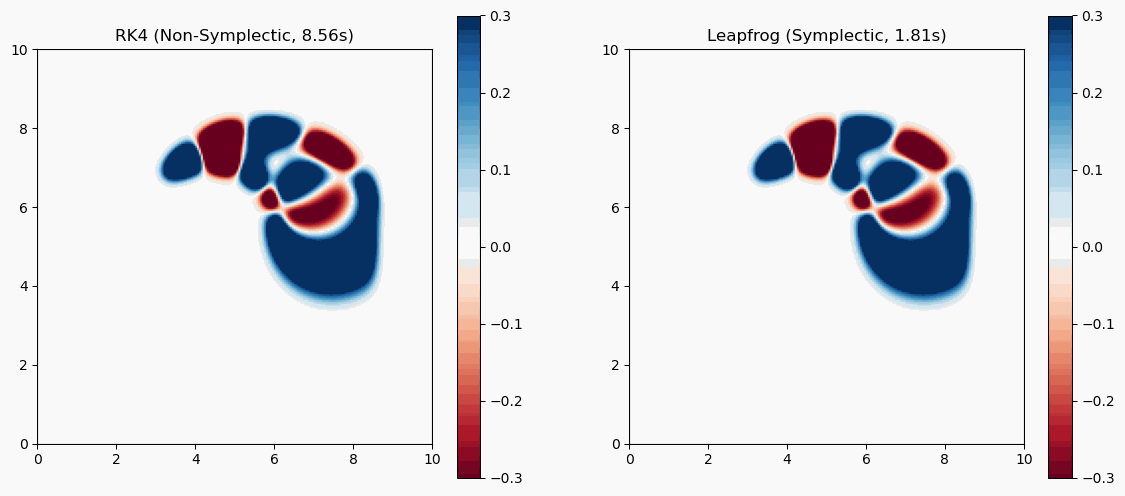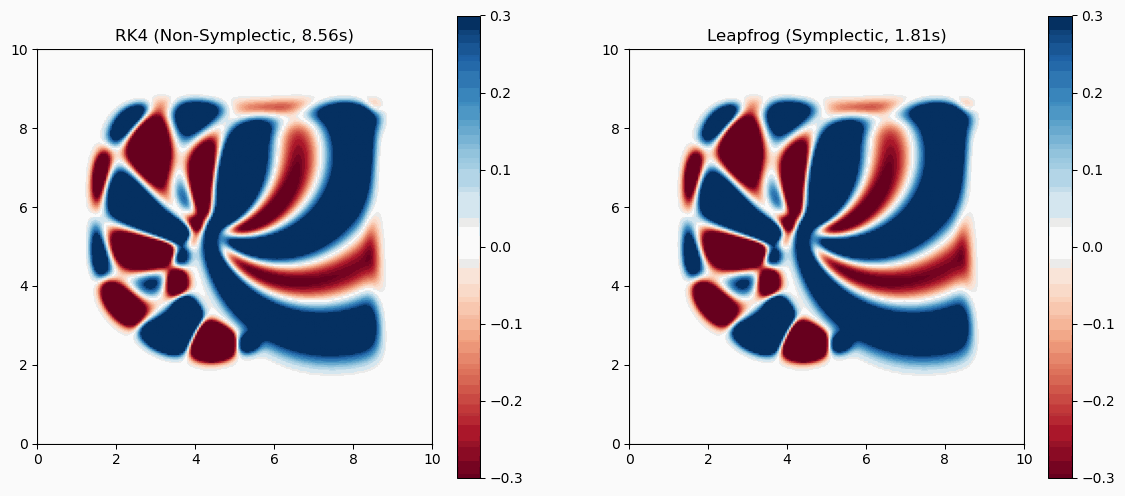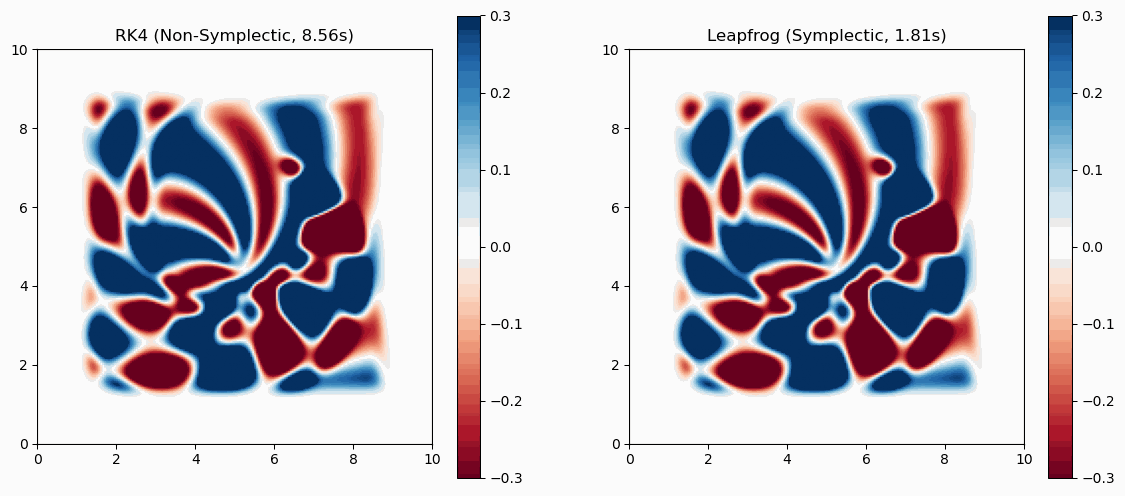
While standard matrix multiplications are multi-threaded and highly optimized, mmx and mtimesx still provide substantial performance boosts when performing operations on ND-arrays or ND-matrices.